This post shows how to setup Squirrel SQL client for Hive, Drill, and Impala on Mac. I assume Mac client is already setup and this is the case with MapR 5.2.1 and MEP 3.0. Change the version numbers if you set up with other MapR or MEP versions.
Install Squirrel
Go to http://www.squirrelsql.org/#installation and follow the instruction.
Then, Launch Squirrel App from Application Directory.
Use Hive from Squirrel
You have to follow three steps, bring jars, configuration, and run the query. Let’s see each detail.
Bring jars
Bring jars from cluster node with hive installed. You need to bring these jars below (assuming you use MR2).
/opt/mapr/hive/hive-2.1/lib/commons-logging-1.2.jar
/opt/mapr/hive/hive-2.1/lib/libfb303-0.9.3.jar
/opt/mapr/hive/hive-2.1/lib/libthrift-0.9.3.jar
/opt/mapr/hive/hive-2.1/lib/httpcore-4.4.jar
/opt/mapr/hive/hive-2.1/lib/httpclient-4.4.jar
/opt/mapr/hive/hive-2.1/lib/hive-shims-2.1.1-mapr-1703.jar
/opt/mapr/hive/hive-2.1/lib/hive-service-2.1.1-mapr-1703.jar
/opt/mapr/hive/hive-2.1/lib/hive-metastore-2.1.1-mapr-1703.jar
/opt/mapr/hive/hive-2.1/lib/hive-exec-2.1.1-mapr-1703.jar
/opt/mapr/hive/hive-2.1/lib/hive-jdbc-2.1.1-mapr-1703.jar
/opt/mapr/hive/hive-2.1/lib/guava-14.0.1.jar
/opt/mapr/hadoop/hadoop-2.7.0/share/hadoop/common/hadoop-common-2.7.0-mapr-1703.jar
/opt/mapr/lib/slf4j-*
Then, put those jars into some directory such as $HOME/squirrel/hive or something.
Configuration
Create Drivers and Aliases with those jars brought from cluster nodes.
- Click “Drivers” on the upper left side
- Click Green Cross
- On the window, put some Name like MapR Hive
- Fill in Example URL with the hiveserver2 node and port on the cluster, such as jdbc:hive2://cent62:10000
- Click “Extra Class Path”
- Click “Add” and choose the jar folder we put the jars above, and select all the jars.
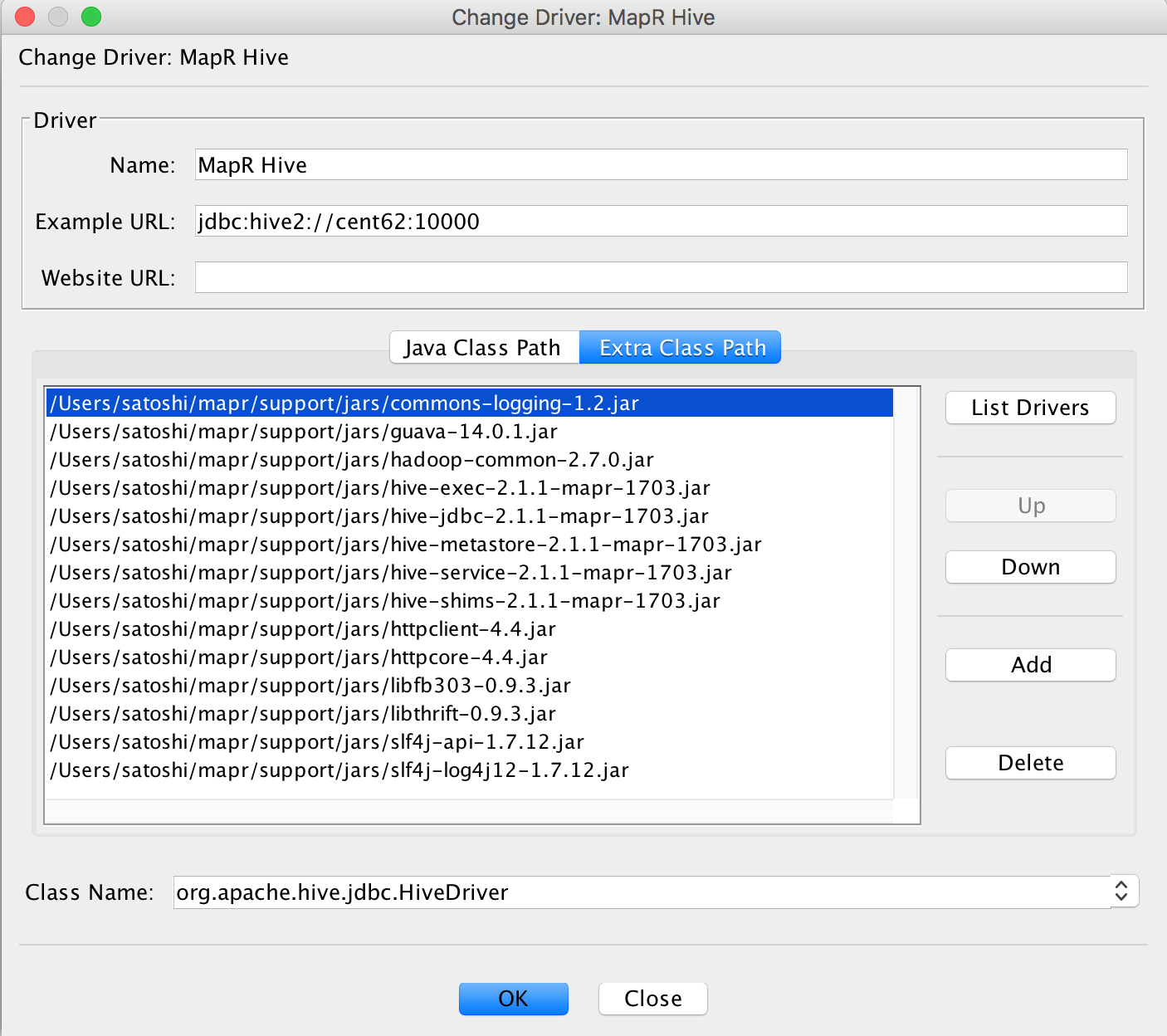
- Fill in the “Class Name” with “org.apache.hive.jdbc.HiveDriver”. Then, click OK.
- Click on “Aliases” on the upper left side.
- Click Green Cross.
- Put some Name like “Hive on Cent6”
- Choose the Drive we made on the step 7.
- Confirm the URL for hiveserver2 is correct. Modify if wrong.
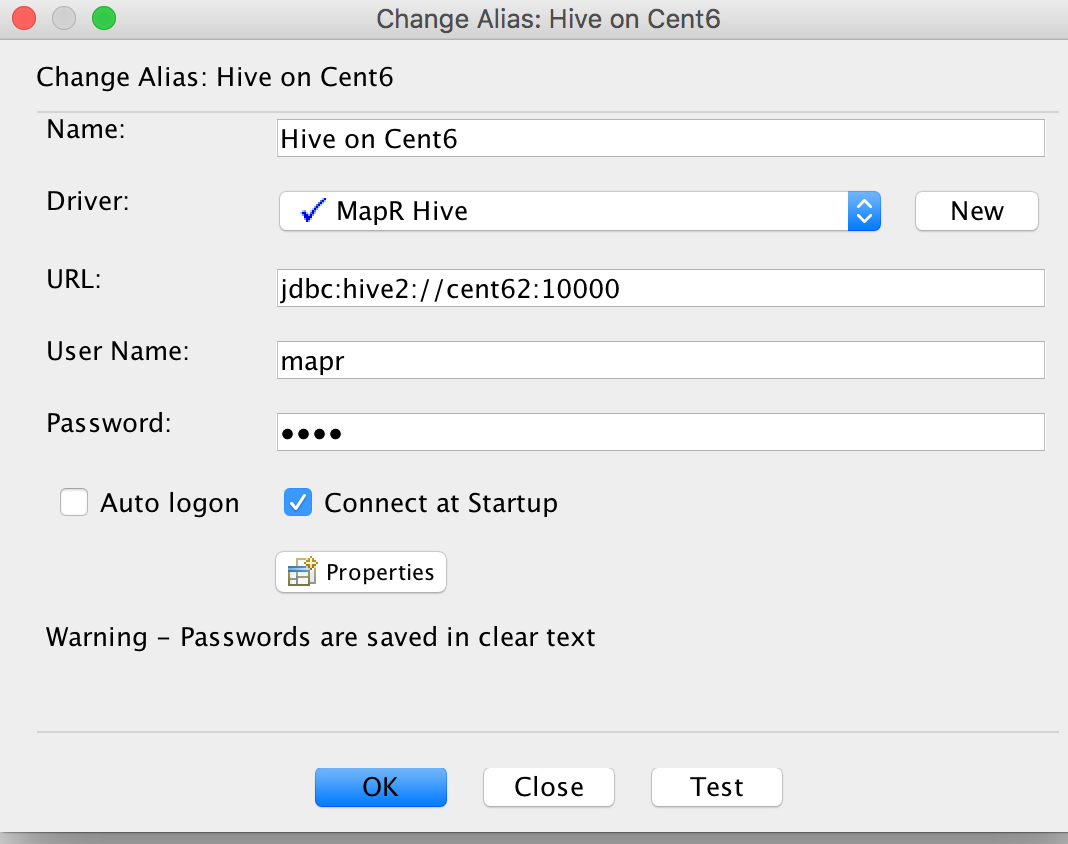
- Fill in User and Password.
- Click “Test”
- Fill in User and Password, then click “Connect”
- If succeeded, you are ready to go!
- Click “OK”
Run Hive Query
- Click Aliases and double click the alias you just made.
- On the popup window, click “Connect”
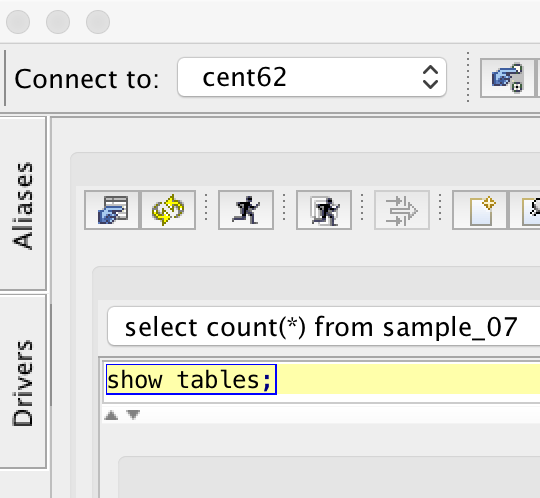
- Click “SQL” on upper middle section to execute queries
- Click yellow highlighted sections and enter some queries
- Then, click the icon of running man on upper left side or press Control-Enter, which will run the query and give you the result
Use Drill from Squirrel
Using Drill case is mostly described here, but I’ll show you the steps anyways.
Bring jars
For Drill, you have to bring jars from this URL
Configuration
Basically follow the same step as shown in Hive case.
- Create Drivers as follows
- Use jdbc:drill:zk=/drill/ to fill Example URL
- cluster-id is “${cluster name}-drillbits” by default and specified at /opt/mapr/drill/drill-1.10.0/conf/drill-override.conf
- add the jars above to Extra Class Path
- Use “com.mapr.drill.jdbc41.Drive” for Class Name
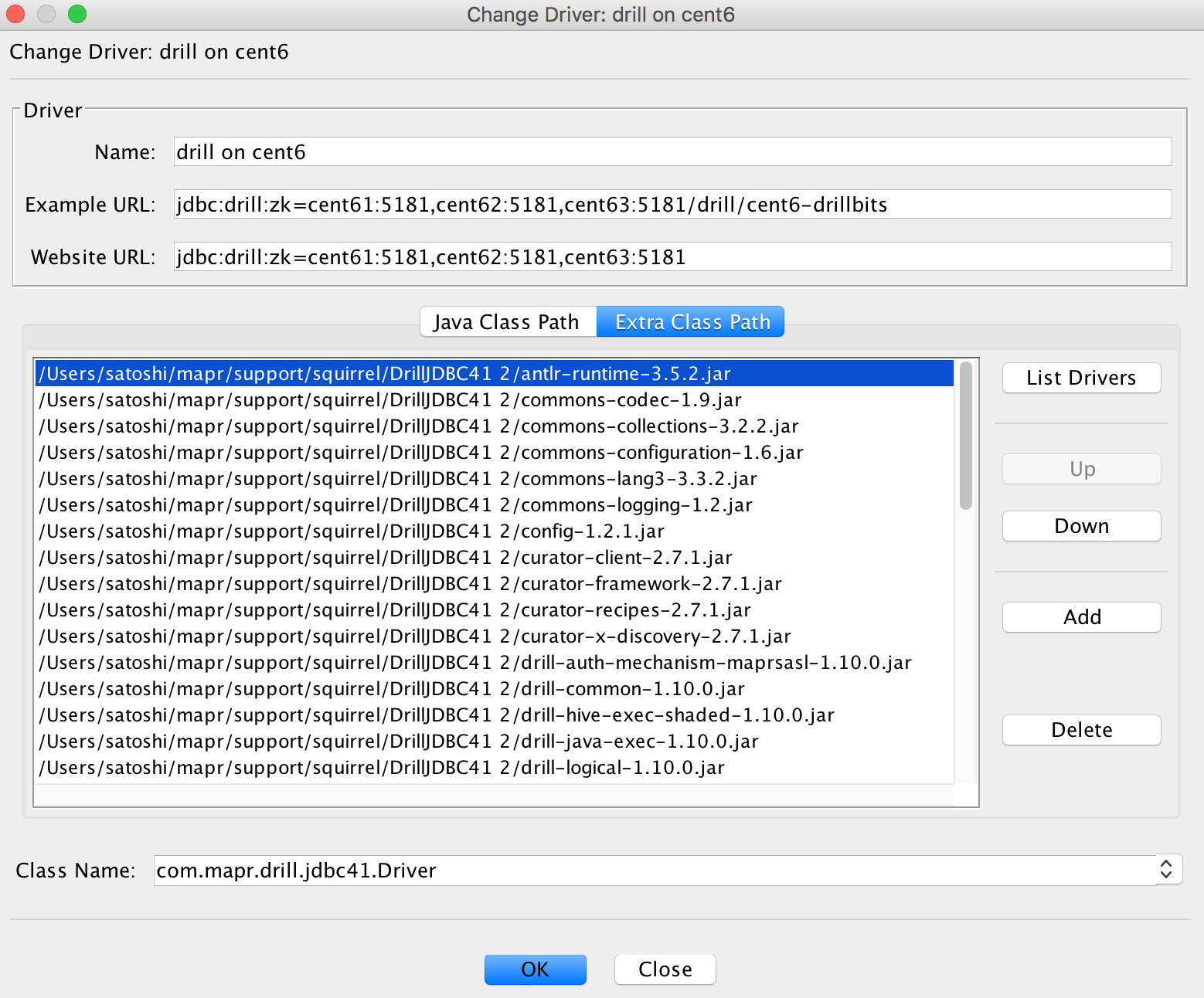
- Use jdbc:drill:zk=/drill/ to fill Example URL
- Create Aliases with the Drive above. If connection test is successful, you are ready to go!
Run Drill Query
This is almost the same process as Hive.
If you haven’t enabled Hive storage format,
enable it before connection to query Hive table.
After connection, Squirrel shows the enabled storages.
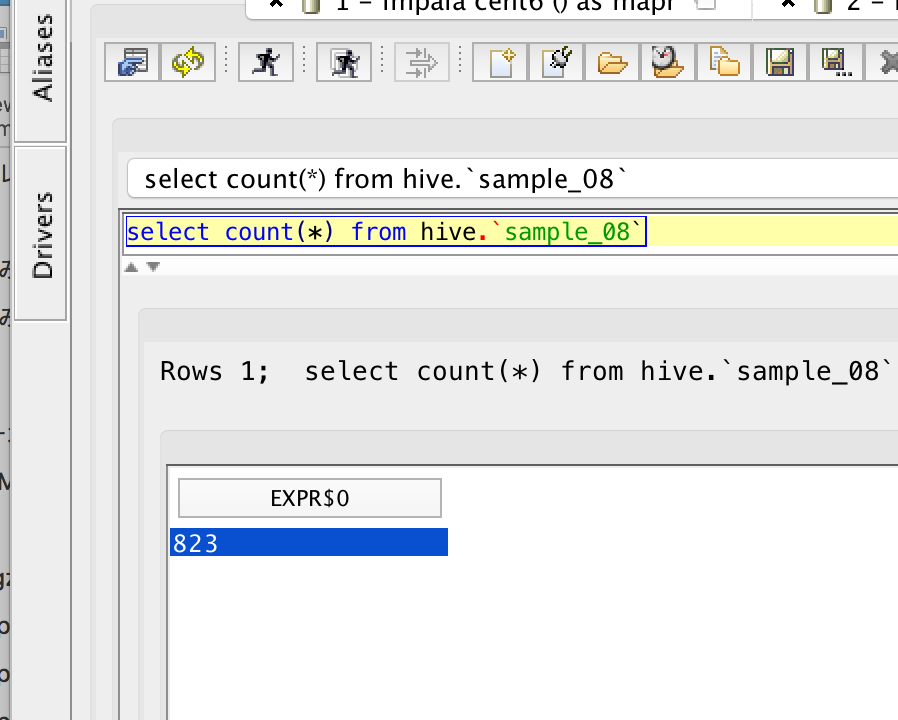
Now you can query Hive table from Drill.
Use Impala from Squirrel
The essence of using Impala from jdbc connection is also described here, but I’ll show the steps anyways.
jars and Configurations
You can use the same jars and drivers as Hive case.
Make Aliases and specify Impala server URL and port as jdbc:hive2://:21050/;auth=noSasl
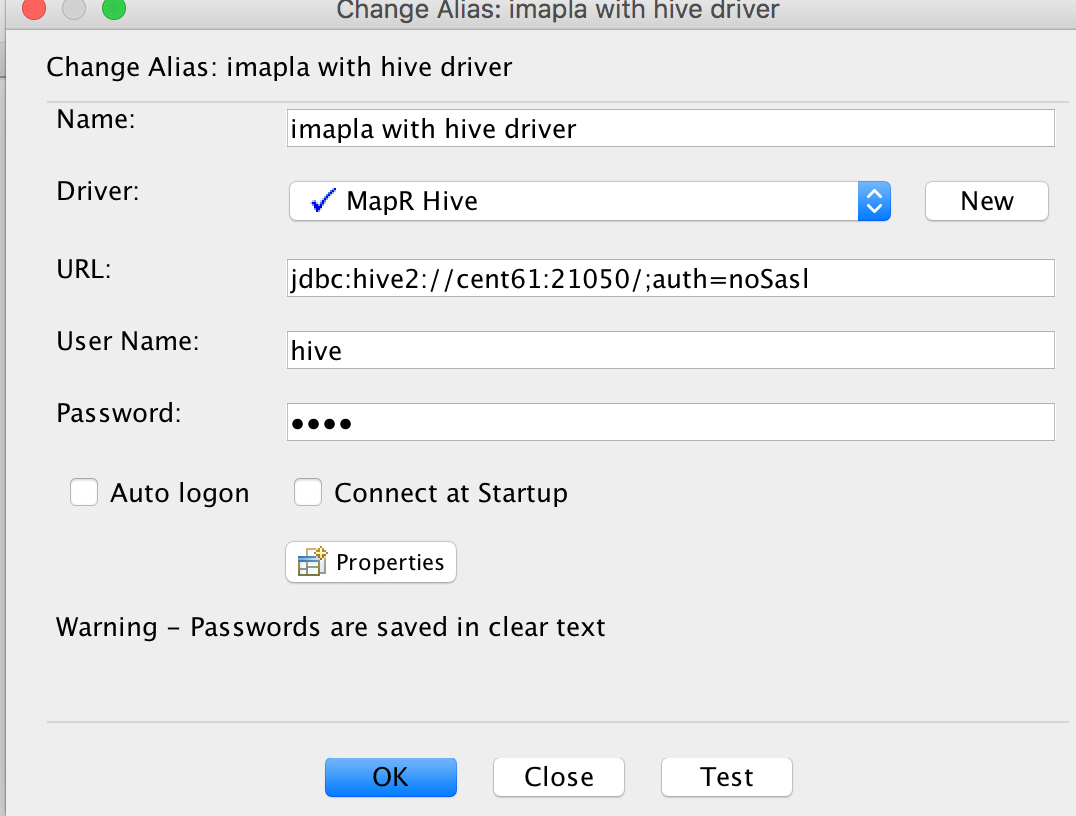
Run Impala Query
Running Impala Query is the same as running hive query.